Всё просто.
def uv2dir(u, v):
'''
Источник:
https://github.com/blaylockbk/Ute_WRF/blob/master/functions/wind_calcs.py
'''
import numpy as np
direction = (270 - np.rad2deg(np.arctan2(v, u))) % 360
veloctity = np.sqrt(np.square(u) + np.square(v))
return direction, velocity
Дъявол в мелочах))
Во-первых, нужно передавать аргументы в arctan2 именно в порядке V, U (сначала Y, потом X). Об этом написано в строке документации функции. Дополнительно можно прочитать на странице Wind Direction Quick Reference от NCAR/UCAR. Вот цитата оттуда:
"This discussion assumes that the two-argument arctangent function, atan2(y,x), returns the arctangent of y/x in the range -π to π radians, -180 to 180 degrees. C, C++, Python, Fortran, Java, IDL, MATLAB and R all follow this convention.
Warning: Spreadsheets, including Microsoft Excel, LibreOffice Calc and Google Docs switch the arguments, so that atan2(x,y) is the arctangent of y/x.
To check your software, compute atan2(1,-1). If it equals 2.36 radians (135 degrees) then your software uses the programming language convention and you can use these formulas unchanged. If it equals -0.79 radians (-45 degrees) then your software follows the spreadsheet convention and you must switch the arguments of atan2 in the following equations." и сначала python-овская функция arctan2."
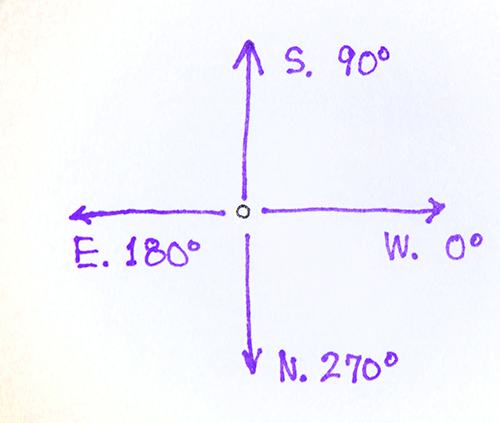
Во-вторых, повороты координатных осей с целью получить именно метеорологическое направление ветра. По традиции в метеорологии:
- название ветра указывает ОТКУДА он дует. Так южный ветер дуют с юга, а восточный - с востока. Напомню, что для морских течений наоборот;
- Южный и западный ветра ассоциируются с положительными направлениями компонент ветра V и U соответственно.